Learning a Restricted Bayesian Network for Object Detection
Henry Schneiderman
Abstract: many classes of images have the characteristics of sparse structuring of statistical dependency and the presence of conditional independencies among various groups of variables. Such characteristics make it possible to construct a powerful classifier by only representing the strong direct dependencies among the variables. In particular, Bayesian network compactly represents such structuring. However, learning the structure of a Bayesian network is known to be NP complete. The high dimensionality of images makes structure learning especially challenging. This paper describes an algorithm that searches for the structure of a Bayesian network based classifier in this large space of possible structures. The algorithm seeks to optimize two possible cost functions: a localized error in the log-likelihood ratio function to restrict the structure and a global classification error to choose the final structure of the network. The final network structure is restricted such that the search can take advantage of pre-computed estimates and evaluations. We use this method to automatically train detectors of frontal faces, eyes, and the iris of the human eye. In particular, the frontal face detector achieves state-of-the-art performance on the MIT_CMU test set for face detection.
paper here
Bayesian Network: directed acyclic graph G and a set P of probability distributions, where nodes and arcs in g represent random variables and direct correlations between variables respectively. P is the set of local distributions for each node. Goal of learning a BN is to determine both the structure of the network (structure learning) and the set of conditional probability tables CPT’s (parameter learning) learning the structure, or causal dependencies of a graphical model of probability such as a Bayesian network is the first step in reasoning under uncertainty. The structure encodes variable independencies.
— A Bayesian Network based Approach for Data Classification using Structural Learning
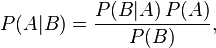
Pyramid (image processing)
type of multi-scale signal representation in which a signal or an image is subjected to repeated smoothing and subsampling
two types:
- lowpass – lowpass pyramid made by smoothing an image with an appropriate smoothing filter and then subsampling the smooth image
- resulted image is subjected to the same procedure, and the cycle repeated multiple times
- results in a smaller image with increased smoothing
- bandpass pyramid – made by forming the difference between images and adjacent levels in the pyramid and performing image interpolation between adjacent levels of resolution, to enable computation of pixelwise differences
Intro:
classes of images have sparse structuring of statistical dependency.
- each variable has a strong statistical dependency with a small number of other variables and negligible dependency with the remaining ones.
- ex: geometrically aligned images of faces, cars, and telephones
- empirical mutual information among wavelet variables representing frontal human face images fig1
- mutual information – measure the strength of the statistical dependence between two variables
- each image represents the mutual information values between one chosen wavelet variable
- Sparse structuring of statistical dependency: empirical success of “parts-based” methods for face detection and face recognition.
- methods concentrate modeling power on localized regions, in which the dependencies tend to be strong
- statistical dependency is not always decomposable into separate parts
- non-decomposability of statistical dependency can be compactly represented using conditional independence
- Graphical models provide parameterizations that can compactly capture such behavior
- use for classification in a generative framework with a separate graphical model (e.g. Bayesian network) representing each class-conditional probability distribution
- Challenge of learning the structure of a Bayesian network since it is NP complete
- only guaranteed optimal solution is to construct classifiers over every possible network structure and explicitly compare their performance
- Heuristic search the only possible means of finding a solution
- Proposed approach:
- selects a structure by optimizing a sequence of two cost functions:
- optimization over local error in the log likelihood ratio function
- assume every pair of variables is independent from the remaining variables
- organize the variables into a large number of candidate subsets such that this measure is minimized ; restricts the final network to representing dependencies that occur only within subsets
- optimization in choosing the final network structure by minimizing a global measure of empirical classification error computed on a cross-validation set of images
- global measures present a complexity challenge
- cost of computing classification error score
- conditional probability
- functions over the entire set of training images
- high dimensional problems
- such as image classification require a large set of examples
- cross validation cost
- number of possible structures in this reduced space of possible
- structure is large
- cost of computing classification error score
- Restrict the final network to consist of two layers of nodes
- nodes in the top layer consist of a single variable
- nodes in the second layer each consist of a subset of variables
- assumed that the parents of any node in the second layer are statistically independent
- makes it possible to find the final structure using pre-computed estimates and evaluations over the candidate subsets and the individual variables
- Detector exhaustively scans a classifier over the input image and resized versions of the input image
- classifier operates on fixed size input window
- 32×24 for frontal faces
- allows for a limited amount of variation in size and alignment of the object within this window
- construct classifier for detecting several types of objects
- global measures present a complexity challenge
- Construction of the Classifier
- f(x1, …, xn l log P(x1,…xn|w1) / P (x1,..xn)=|w2)
- x1 .. xn input variables and in object detection class the input is a wavelet transform of the gray-scale image window
- w1 and w2 indicate the two classes (object and nonobject)
- construct the classifier using geometrically aligned images of the object for class w1, and various non-object images for class w2
- two aspects to constructing the classifier:
- learning the Bayesian network structure and estimating probability distributions that form the network
- Minimizing Local Error
- create a large collection of subsets of variables
- grouping enables efficient search using global classification error metric
- subsets formed by considering two types of modeling error:
- not modeling the dependency between two variables
- not modeling a variable
- evaluate the cost of these modeling errors in terms of their impact on the log-likelihood ratio function
- seek a set of candidate subsets, G, to minimize the localized error function
- assign the candidates to n subsets using n greedy searches, where each input variable xi is a seed for one search.
- guarantees every variable is initially represented in at least on subset
- each greedy search adds new variables by choosing the one that has the largest sum of c1 values formed by its pairing with all current members of the subset
- guarantees any variable with any subset will have strong statistical dependency with each other
- Reducing Dimensionality over Subsets
- represent probability distributions over all candidate subsets
- full joint probability distribution dimensionality will be too great
- perform dimensionality reduction on each subset by linear projection
- Estimating Probability Distributions
- represent distribution by a table
- discretizes each of the linear projections Fk, to a discrete feature value by vector quantization
- probability table estimated by counting the frequency of occurrence of each possible value of Fk in the training data
- Estimate marginal probability distributions for each input variable X1..Xn
- represent distribution by a table
- represent probability distributions over all candidate subsets
- Minimizing Classification Error
- make the final choice of a Bayesian network
- select r of the q subsets
- search for the choice that minimizes empirical classification error over a set of labeled examples
- measure performance using the area underneath the receiver operating characteristic curve
- select r of the q subsets
- make the final choice of a Bayesian network
- create a large collection of subsets of variables
- selects a structure by optimizing a sequence of two cost functions:
